私の情報整理術
コンピュータを活用して情報を整理する技術を紹介する書籍や記事が増えています。 オンライン書店で「情報整理」を検索すると300冊を越える書籍がヒットします。 大学教授・成功した経営者・ジャーナリストなど、 様々な職種の人々が情報整理のためのコンピュータ活用術を紹介しているようですが、 コンピュータの専門家による情報整理術の紹介本はほとんど無く、 既存のシステムをうまく使う工夫について書かれたものばかりが 世に出ているように見うけられます。一方、既存システムを独自に改良したり新しいシステムを開発したりして 効果的な整理術を駆使しているコンピュータ専門家は多いはずです。 今回の連載では、 このような情報整理術の達人方に登場していただき、 彼等がいかに情報整理を行なっているかを披露してもらいます。
連載の第1回目は私の情報整理手法を紹介させていただきます。 私は情報整理の達人でも何でもありませんが、 片付けや整理の不得手には自信があるので、 長年にわたって情報整理のためのシステムを工夫してきました。 情報整理が得意な人は情報整理術など駆使しなくても困らないはずですから、 情報整理が苦手な人ほど情報整理術については詳しいはずであり、 その点では私は充分資格がありそうです。
情報整理の方針
長年いろいろな情報整理術を試してきた経験上、 以下のような方針が大事だと考えています。- 単純な方法を使う
- 手間のかかる整理術は長続きしません。 運用が簡単でかつ効果が大きい方法を使うべきでしょう。
- 情報は一箇所にまとめる
- 情報が分散していると、捜すのが面倒ですし、 ダブルブッキングのような危険も発生しがちです。 情報は一箇所で扱うようにしておけば安全です。
- 各種の機器を活用する
- 全予定を携帯電話で管理することにすれば予定情報は一元化されますが、 入力が大変ですし一覧印刷もできません。 パソコンが使えるときはパソコンで/携帯電話しか使えないときは携帯電話で/といった具合に、 状況に応じていろいろな機器を使えるようにしておけば便利です。
- 汎用性を重視する
- いろいろな環境で情報を利用できるようにするため、 特殊なデータベース形式は利用せず、なるべく単純なテキストファイルなどを利用します。
- 情報は消さない
- 情報を編集するとき、 古い情報は消さずに残しておいて、新しい情報だけ使うようにしておきます。 最近はふんだんにディスクを使用することができますから、 小さな古い情報はまったく消さないことにしておけば安全です。
- 検索技術を駆使する
- 検索のためにファイル名やディレクトリの名前や構造を工夫したり、 キーワードを付加しておいたりといった整理術は 面倒ですから長続きしそうもありません。 適切な検索技術を使うことによりなるべく手間がかからないようにします。
具体的な方法
このような方針にもとづき、私は以下のような情報整理方法を使っています。サーバで情報を一元的に管理
私はインターネットに接続されたひとつのLinuxマシン上にあらゆる情報を集めています。 メールはこのマシンのIMAPサーバ上に保存しているので、 各種のメーラを使ってネット上のどこからでも読むことができます。 メモや予定表は後述のWikiを利用しており、 プログラムファイルや論文などはSubversionレポジトリで管理しています。 このように、大事なファイルはほとんどすべてサーバ上に置くようにしているので、 パソコンを買いかえてもデータ移行にはあまり苦労していません。Wikiの利用
ちょっとしたメモや日記、TODOリスト、予定表などは 自作のWiki(Wiki Wiki Web)で管理しています。 Wikiページのリストは図1のように新しいものから順番に参照できます。 タイトルの左のまだら模様はアクセス履歴を表現したもので、 アクセスが多いページほど黒い筋が表示されます。
図1: Wikiページのリスト
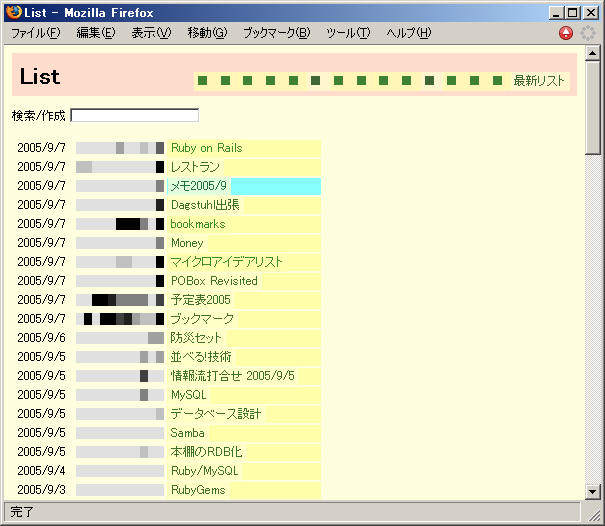
図2はWikiページの例です。 「Ruby on Rails」のページを編集して更新したとき、 古いページは図1のリストには表示されなくなりますが、 「履歴」をクリックすると参照することができます。
図2: Wikiページの例
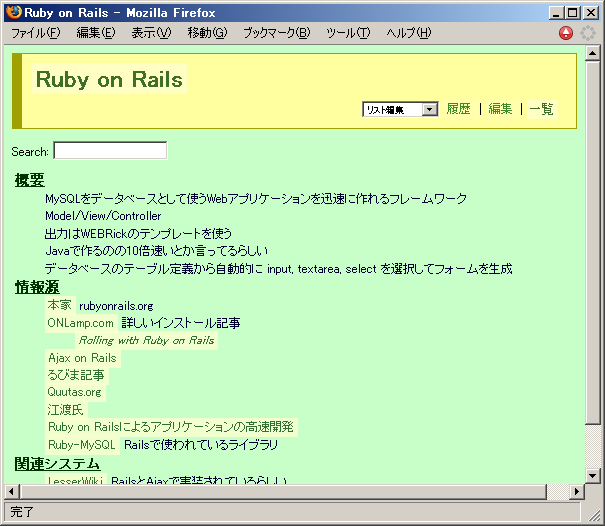
Wikiページに書き込む情報は比較的単純なテキストなので、 PDAや携帯電話と簡単にデータをやりとりすることができます。 このWikiのデータはPalmの「メモ帳」と同期できますし、 携帯電話などからはメールで読み書きできるようになっています。 たとえば下のようなメールを送ると「レストラン」ページの情報をメールで受け取る ことができますし、 アイデアやメモを携帯電話経由でWikiに書き込むこともできます。
To: masui@pitecan.com Subject: Wiki? レストラン
サーバ上での情報検索
最近は各種の全文検索システムが公開されていますから、 サーバ上のWikiデータやメールなどをキーワードするのは簡単になってきました。 私はGETAと FreyaSX という全文検索システムを使ってブラウザから検索ができるようにしています。情報間の距離を利用して、中身が近い情報をたどることによって情報検索を行なう 「近傍検索」という方法も利用しています。 昔会った人の写真を捜そうとするとき、 写真にキーワードが添付されていなくても、 会ったときのイベント名などのキーワードがわかれば、 メールやメモをキーワード検索してからその日の写真を捜すことによって 写真をみつけることができます。 また、私は手持ちのすべてのデジカメ写真の撮影場所をデータベース化しているので、 会った場所がわかれば、その場所の位置情報をもとに検索することもできます。 あらゆる写真の位置情報をデータベース化するのは結構大変でしたが、 私はGPS携帯などを使って移動経路を記録しているので、 最近撮った写真については自動的に位置情報を付加しています。
図3: 近傍検索システム
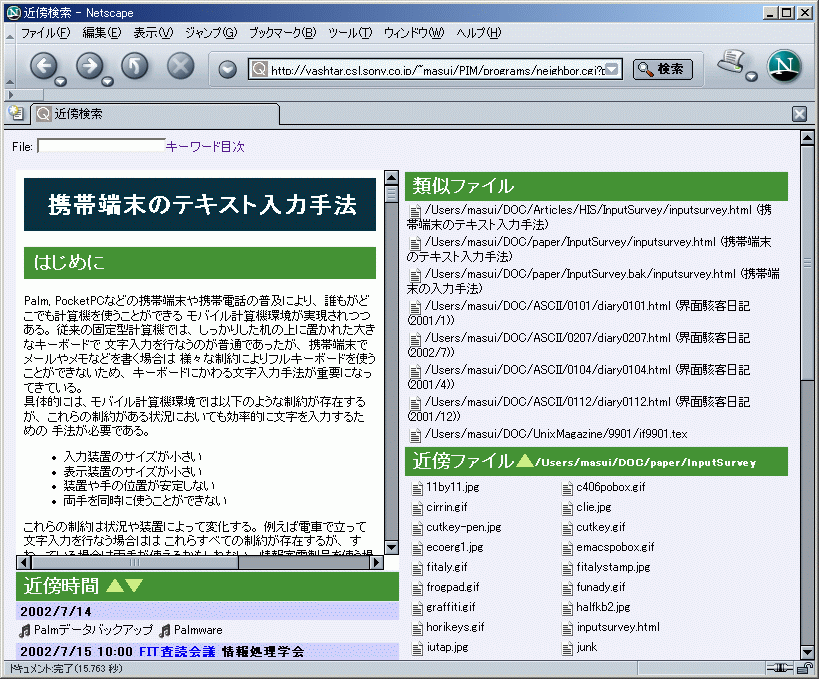
図3の近傍検索システムでは、 「携帯端末のテキスト入力法」というページに内容が近いファイル・ 置き場所が近いファイル・ 作成日付が近い近傍ファイルがリストされています。 このうちひとつを選択すると、 そのファイルを中心としてまた近傍ファイル群が表示されるので、 近さにもとづいて手持ちのファイルをどんどんたぐっていくことができます。
その他の工夫
図4: 何度も編集を繰り返しているWikiページ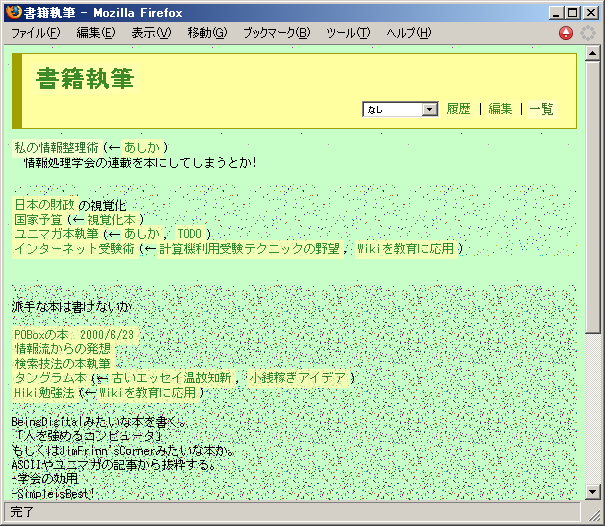
- 古い情報が古く見える
- 図4のページは場所によって背景パタンが異なっています。 昔作成した部分は背景パタンが黒っぽく/最近編集した部分は白っぽくなっているため、 ページ内の情報の古さがなんとなくわかるようになっています。
- 逆リンクの活用
- 図4で「(←視覚化本)」のように表示されている部分は自動生成されたリンクです。 このページと「視覚化本」というページの両方から「国家予算」のページにリンクが貼ってあるため、 ページの関連を示すためにこのようなリンクを自動生成しています。
- メモの一元化
- ネットに接続されてないときパソコン上でメモを書いた場合、 そのメモには日付/時刻のIDをつけてWikiに後で転送するようにしています。 いろいろなパソコン上でメモを書いた場合でも メモはすべてWiki上でマージされることになります。
- ブックマークをサーバに置く
- ブラウザごとにブックマークが異なっていると不便なので ブックマークもサーバ上のものを使うようにしています。
- ランダムにメモや写真をブラウズする
- メモや写真が増えてくると、古い情報を忘れてしまいがちです。 古いメモや写真をランダムに表示するシステムを使って温故知新しています。
- Wikiページの直接編集
- Wikiページを編集する場合は「編集」ボタンを押して編集モードにしてから テキスト編集を行ない、最後に「書込」ボタンを押して書き込みを行なうのが普通ですが、 このような操作は非常に面倒なので直接編集できるような工夫をしています。
展望
以上のような法により、 テキスト情報に関してはかなり整理ができるようになりましたが、 写真や絵などの整理はまだ完全ではありません。 また、紙の文書や名刺などをコンピュータ上の情報と関連づける方法も まだあまりうまくいっていないので、 いろいろ工夫していきたいと思っています。次回は...