(これまでの増井俊之の「界面潮流」はこちら)
下図はMacintoshの Disk Inventory X というソフトで私のホームディレクトリの中のファイルの大きさを視覚化したものです。
大きなファイルが大きな矩形で表現され、ファイルをまとめたフォルダも矩形として階層的に表現されています。

一方、下図はWindowsの SequoiaView というソフトを使ってファイルの大きさを視覚化した例です。
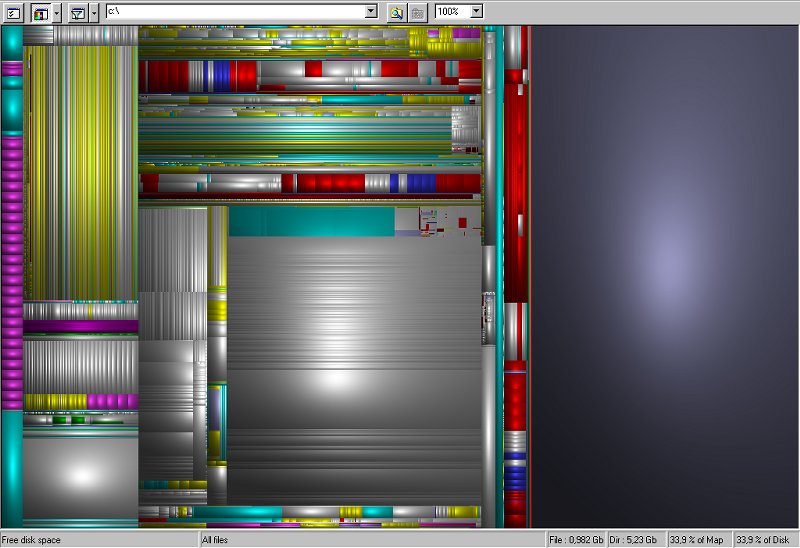
後発のDisk Inventory Xは、おそらく SequoiaView に触発されたと思われるので外見がよく似ていますが、階層的に配置した矩形の集合でファイルサイズを表現するという方法は、University of Maryland の Human-Computer Interaction Lab で開発された TreeMap というシステムに端を発しています。
ディスクの中にどんな大きさのファイルがどれほどあるのかはわかりにくいものですが、TreeMap のような方法を使うと大きなファイルの分布を直感的に把握することができます。
このように、大量の情報をうまく画面上に表示することによって理解を助けるテクニックを「情報視覚化(Information Visualization)」と呼びます。
■情報視覚化の歴史
情報視覚化の研究は、1990年頃からXerox PARCなどで盛んになりました。PARCでは、様々な大量の情報を3次元空間にマッピングすることによって、情報をひとつの2次元画面上に表示する手法が主に研究されていました。
3次元空間のデータを眺める場合、遠くにあるものは小さく見えますから、データをうまく配置すれば自然に沢山の情報を表示することができます。たとえば古い情報は3次元空間内の遠くの方に配置し、新しい情報は近くに配置すれば、CGに利用される3次元表示手法を使って、「近くの新しい情報は大きく/遠くの古い情報は小さく」表示することが可能になります。
下図の“Perspective Wall”システムでは、沢山のファイルを3次元空間上の「壁」に貼り付けることによって、注目している範囲の情報だけが大きく見えるようになっています。

1990年当時は高速3次元表示が可能な計算機は高価だったので、このような研究を行なえる場所は限られていました。また、視覚化が必要なほど大規模な情報もあまり利用できませんでしたから、そのころ提案された情報視覚化手法はほとんど実用的に利用されることはありませんでした。
一方、最近はどんなパソコンでも高速にグラフィクス表示を行なうことができますし、Web上の大規模なデータが簡単に入手できるようになってきました。パソコンの中にはかなりの量のファイルが入っているのが普通ですし、Web上には何千万件単位のデータが沢山あります。
Ben Shneiderman氏の「TreeMapの歴史」というページにはTreeMapの20年の歴史が解説されていますが、情報視覚化の研究が始まって20年たって、ようやく本格的な応用が見えてきたようです。
■情報視覚化の手法
大量の情報をまんべんなく画面に表示することはできませんから、なんらかの方法で必要な部分だけを表示しなければなりません。
スクロールバーのような一般的なGUI部品を使って情報の一部だけ表示することも可能ですが、巨大なデータをスクロールだけで扱うことは難しいので、なんらかのフィルタリング手法やズーミング手法が必要になります。
特に、全体の構造を把握しつつ詳細情報も調べられるような、“Focus + Context”を考慮した手法が重要です。
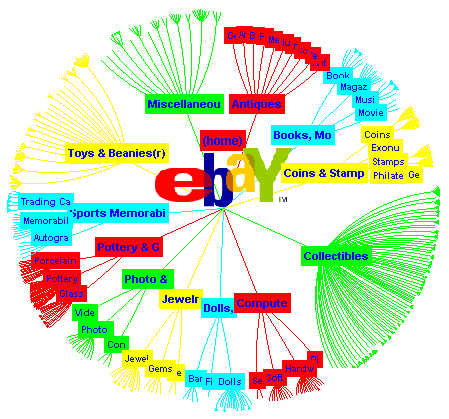
下図は、大規模なネットワーク情報を円板上に配置する“HyperbolicTree”という情報視覚化手法の例です。
この HyperbolicTree も、90年代にPARCで開発されたもので、現在注目しているノードを画面の中央に置き、その親ノードと子ノードをその周囲に配置することを繰り返すことによって、すべてのノードを円板内に表示するというものです。
中心から遠くなるほどノードやリンクを小さく表示することにより、どれほど大きなデータでも画面内におさまるようにすることができます。
HyperbolicTree は、PARCから分離した Inxight というベンチャー企業で“StarTree”という名前で販売されていましたが、現在は Business Objects というSAPの子会社に買収されて、そこで販売されているようです。
私は、“Focus + Context”を考慮して大規模な階層構造を視覚化できる LensBar というシステムを開発しています。
LensBarでは、ユーザがマウスを左右に動かすことによって、リストのズーミング操作を行ないます。これによって、すべてのデータを表示したり、重要なデータだけ間引いて表示したりすることができます。
また、検索キーワードを指定することにより、キーワードにマッチするエントリのみを表示対象とすることができるので、フィルタリングにより表示量を制御しつつ全体と詳細を同時にブラウズすることが可能になっています。
以下の動画は、Cプログラムのテキストをズーミングしたりフィルタリングしたりしているところです。マウスを左にドラッグしてズームアウトすると、関数名など重要なところだけ表示されます。
文字を入力するとマッチする行だけフィルタリングされ、現在表示可能な行が左のスクロールバーの背景に表示されます。フィルタリングしている状態でズーミング操作を行なうと、指定したパタンにマッチしている行と重要な行が両方表示されるので、プログラム全体においてマッチした行がどのように分布しているのかがわかります。
私が運営している「本棚.org」という書籍情報共有サイトでは、情報視覚化の本棚という「本棚」が作ってあり、下図のように情報視覚化に関連する各種の書籍が登録されています。
情報視覚化と銘うった日本語書籍はほとんどありませんが、“Information Visualization”をタイトルに含む洋書はすでに沢山出版されています。
ハイパーテキストの研究成果が、Webという形で世の中に浸透するのに20年かかりました。全文テキスト検索の研究が、AltaVista をはじめとする検索エンジンとして世の中に広まるのにも20年かかりました。
いよいよ情報視覚化の研究が世の中で注目される時代が近付いているような気がします。