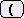 )
によりマクロ定義開始を指示し,
その後のキー操作でマクロとして定義したい編集作業を行ない,
最後に別のキー操作
(通常
)
によりマクロ定義開始を指示し,
その後のキー操作でマクロとして定義したい編集作業を行ない,
最後に別のキー操作
(通常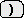 )
によりマクロ定義終了を指示する.
これにより定義されたマクロは
マクロ呼び出しを指令するキー操作
(通常
)
によりマクロ定義終了を指示する.
これにより定義されたマクロは
マクロ呼び出しを指令するキー操作
(通常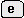 )
により実行される.
)
により実行される.
増井俊之, 中山 健
コンピュータソフトウェア, Vol.11, No.6(1994), pp.484-492.
本論文中のシステムはJava対応ブラウザで実際に使ってみることが可能です。
2.3.4節を参照下さい。
GNU Emacs用プログラム
dmacro.elも配付しています。
テキストエディタにおいてユーザの操作の繰り返しから次の 操作を予測してマクロとして定義し実行する「動的マクロ生成機能」と, 辞書や文脈知識などを用いた各種の予測実行機能を 組み合わせて使用することにより,ふたつのキーを使用するだけで, 繰り返し操作の検出実行/予測手法の選択/選択された 予測結果の繰り返し適用といった各種の予測インタフェースを 実現できることを示す.
近年,操作履歴などからユーザの次の操作を予測するインタフェースや, 例示によるプログラミング の技法を利用したインタフェースの研究が盛んである [3] [11] [14]. グラフィックインタフェースをユーザが操作するときの 繰り返しパタンをシステムが自動的に検出して次の操作を予測する システム[2]や,ユーザの示す例からの汎化により 操作手順を示すプログラムを生成するシステム [1] [5] [6] [7] [10] などの研究が行なわれている.
一方,予測や例示の手法を用いて ファイル編集やコマンド行入力のようなテキスト操作を 簡単化する試みも数多く行われている. DarraghらのReactive Keyboardシステム [4] では,テキストエディタの操作において 以前のキーストロークの頻度情報から次の入力文字列を予測し, 表にして提示してユーザに選択させることにより 障害者やタイピングが苦手な人の補助に成功している. NixのEditing by Exampleシステム[12]では, テキストファイルの多くの部分に同じような修正を行なうとき, 修正前と修正後のテキストの例をユーザがシステムに示すことにより, システムがその変換規則を推論して残りのテキストに対しその変換を 適用することができる. またMoらのTELSシステム[9] では,簡単なテキストエディタ上でのユーザの繰り返し操作から 汎化によりプログラムを生成して以降の操作に適用可能とするが, その際間違いが発見されるとユーザが操作を訂正することにより インクリメンタルにプログラムを修正することができる. ヒューリスティクスにより一番もっともらしい操作が選択される ようになっていることに加え, 修正により正しい条件判断ができるようになっているため, Nixのシステムでは不可能な複雑な処理も 例示のみで指定可能となっている.
しかし各種の研究が行なわれているにもかかわらず, 予測を実行させるための 指定が面倒だったり予測結果が不適当だったりすることが多いために, このような予測/例示インタフェースは実際にはほとんど 使われていないのが現状である. 本稿では, テキスト編集時における操作の繰り返しを検出し実行する機能及び 現在のコンテキストから次の操作を予測実行する機能を組み合わせることに より,単純な枠組みで様々な種類の有用な予測インタフェースを 実現できることを示す. 本システムは1年以上にわたり多くのユーザにより 日常的に使用されることによって実用性が確かめられている.
文書やプログラムを作成/編集するとき,
文字列の検索/修正を繰り返す場合や,
連続する行の先頭に記号を挿入する場合などのように,
ユーザが同じ操作を何度も繰り返さなければならないことがよくある.
前者のように使用頻度の高い操作に対してはエディタが
そのような機能をあらかじめ用意しているのが普通であるが,
後者のようにあまり一般的でない操作を繰り返す場合のためには
「キーボードマクロ」機能が使われる場合が多い.
キーボードマクロとは一連のキー操作を別の簡単なキー操作で
置き換える機能である.
例えばGNU Emacsのキーボードマクロでは
まずユーザが特別のキー操作
(通常)
によりマクロ定義開始を指示し,
その後のキー操作でマクロとして定義したい編集作業を行ない,
最後に別のキー操作
(通常)
によりマクロ定義終了を指示する.
これにより定義されたマクロは
マクロ呼び出しを指令するキー操作
(通常)
により実行される.
キーボードマクロは汎用で便利な機能であるが問題点も存在する. まず,マクロを登録/使用するためには上の例のように 最低3種類の操作が必要であり,定義も呼び出しも面倒である. また,キーボードマクロを使用する場合は 同じ操作を繰り返し実行することを最初から知ったうえで マクロ定義を行なわなければならないが, 実際の編集作業では 同じ操作をユーザが何度か行なって初めて操作の繰り返しに 気づくことも多く, このとき改めてキーボードマクロを登録するのはわずらわしい.
繰り返し作業の効率化のために,
キーボードマクロに代わるものとして,
ユーザの指示により操作の繰り返しをシステムが検出して
繰り返しパタンをマクロとして登録し実行する
動的マクロ生成実行機能(Dynamic Macro: 以降DMと表記)を提案する
[13].
DMではシステムは常にユーザのキー操作の履歴を記憶しており,
ユーザが「繰返し実行キー」(以降 と表記)を入力すると,
システムが履歴から繰り返しパタンを検出してそれをマクロとして登録し
実行する.
例えばユーザが``
と表記)を入力すると,
システムが履歴から繰り返しパタンを検出してそれをマクロとして登録し
実行する.
例えばユーザが``abcabc''と入力した後でを
入力するとDMは`abc''の繰り返しを検出して実行し,
その結果新たな``abc''が入力される.
ここでもう一度を入力すると``abc''がもうひとつ
入力される.
また,ユーザがふたつの行の先頭に``%''を挿入した後
を入力すると,その次の行の先頭に``%''が
入力される.
DMではユーザが覚えなければならないキーはだけであり,
また繰り返し操作を実行した後でも操作をマクロとして登録できるため,
前節で述べたキーボードマクロの問題点が解決されている.
また,DMの仕様は単純であるにもかかわらず,
後の例で示すように,広い範囲の繰り返し処理に適用が可能である.
DMは以下のふたつの規則で構成されている.
が入力される直前に2回続けて全く同じ操作列が
実行されていたとき,その1回分をマクロとして登録し実行する.
そのような繰返しパタンが複数存在するときは最長の繰返しパタンを
選択する.
例えば直前のキー操作が
``abccabcc''
であったときが入力されると,
システムは``abcc''及び``c''の繰返しを検出するが,
``abcc''の方が長いためこちらをマクロとして定義し実行する.
が入力される直前の操作履歴から
XYXというパタンを捜し,存在すれば
パタンXYをマクロとして登録する.
ただし一回目のではYのみ実行する.
このようなパタンが複数存在する場合は最長のXを選択し,
その中で最短のYを選択する.
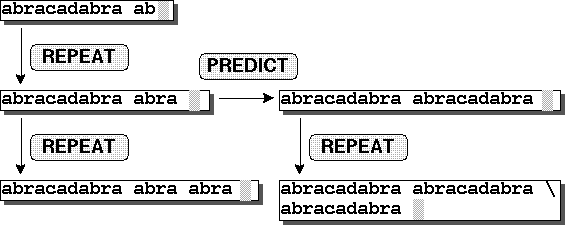
例えば``abracadabra''を入力した後を入力した場合
``abra''をX, ``cad''をYとみなし,
``a''をX, ``br''をYとはみなさない.
ユーザが``abcdabcd''を入力した後でを入力した場合は
規則1が適用され``abcd''が実行される.
また``abcdab''の後でを入力した場合は規則2が適用されて
一回目は``cd''が実行され,もう一度を入力すると今度は
``abcd''が実行される.
このような仕様のため,繰返し操作を行なっているどの時点において
が入力されても適切な予測実行が行なわれる.
ここではGNU Emacs上に実装したDMの使用例を示す.

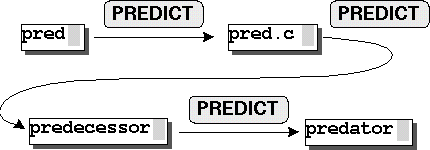
連続する行の先頭に注釈記号を追加する例を図1に示す.
図1(a)が最初の状態である.
ユーザが


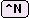
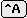 を入力して最初の二行に注釈記号をつけると
(b)の状態になるが,ここでを入力すると
システムは規則1により
の繰り返しを検出し,マクロとして登録し実行して(c)の状態となる.
もう一度を入力すると(d)の状態になる.
を入力して最初の二行に注釈記号をつけると
(b)の状態になるが,ここでを入力すると
システムは規則1により
の繰り返しを検出し,マクロとして登録し実行して(c)の状態となる.
もう一度を入力すると(d)の状態になる.
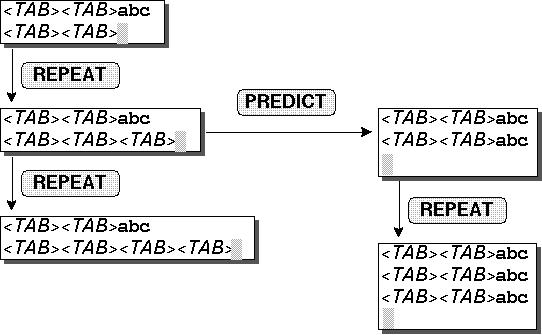
図2. 各行の先頭に注釈記号を追加(2回目の繰り返しが一部だけの場合)

によりこのような結果を得るためには
ユーザは必ずしも同じ操作を完全に2度実行する必要はない.
ユーザが
と入力した後を入力した場合の例を
図2に示す.
この例ではの直前に同じ操作が2度繰り返されていないため,
システムは規則2に従ってXYXというパタンを捜し,
Xとしてを,
またYとして{}を得る.
この結果システムはYを実行し(c)の状態となる.
もう一度を入力するとXYの両方が実行され
(d)の状態となる.
このように,ユーザが操作を繰り返しているどの時点で
を入力しても同様の結果が得られるため,
どのタイミングでを入力するべきかを気にする必要がない.
Nixによる例
[12]
にDMを適用した例を図3に示す.
図3(a)の全ての
``
図3. 文書整形指令の変更([12]の例)}
Nixによる別の例
[12]
にDMを適用した例を図4に示す.
ここではLispプログラム(a)のすべての関数の先頭に
コメントを追加し(b)のようにすることが目標である.
長い変換操作が必要となっているが,
繰り返しの2回目の最初の操作を行なった後で
図4. Lisp関数へのコメント追加([12]の例)
Java対応ブラウザを使用することにより、以下のウィンドウで
実際にDMを試用することが可能である。
Emacsのコマンドのサブセットを使用できる。
DMには以下のような利点がある.
DMの最大の問題点はユーザの期待と異なる予測を実行する可能性が
あることである.例えば,
テキストベースのプログラムにおいて各種の予測手法が現在広く使用されている.
例えばUNIXのシェルでは以前発行したコマンドに対しその省略形を
指定するだけで再実行することのできるヒストリ機能や,
ファイル名の先頭だけ指定すると残りの名前を示してくれる
コンプリーション機能がよく使われているし,
GNU Emacsではテキスト中に既に現われているの別の文字列を参照して
次の入力を予測する
これらの多くのものは,
ユーザの指示により何らかの方法で次の操作を予測して
それをユーザに提示するという型式になっているため,
予測手法毎に異なるキーを割りあてず,
順番に各種予測を適用していくことにより,
単一の「予測キー」(
また前節で示した別の例に対して同じ手法を適用
した結果を図8に示す.
また
最初の
同様の手法を用いて
図10のようにLaTeX文書の作成に応用することもできる.
システムは% 最初の
この
ここで,Sは予測戦略,
Cは現在のコンテキスト,
P,Rはそれぞれ
本システムを多くのEmacsユーザに配付して
1年以上にわたり反応を調査した.
また数人のユーザに予測操作のログを取ってもらうことにより
予測の的中率や実際の使われ方を調査した.
この結果は以下のようになった.
一般に予測インタフェースは以下の要件を満たす必要があると考えられる.
本システムではふたつのキーしか使用しないため
予測のための手間は最小限に押さえられている.
4節で述べたように
予測結果がユーザの期待と一致する確率は非常に高い.
予測実行キーを入力しない限り予測機能は実行されないし
予測に使用する操作履歴を保持することによるオーバーヘッドも小さいため
予測機能を使用しないユーザの邪魔にはならない.
またGNU Emacsでは予測の実行結果は常に
DMによる予測を行なうためには
システムは常にユーザの操作履歴を記憶しておく必要がある.
GNU Emacs Version18は常に100個のキーストローク履歴を保持しており,
現在の実装では規則2のXの長さを1からひとつずつ
増やしながらXYXというパタンを検索しているため,
規則1/規則2を満たす文字列を捜すのに
最悪O(n^2)(nは履歴文字列長)時間が必要であるが,
実際の使用場面においては繰り返されるキーストローク長は
4節で述べたように
平均して3から4程度であり,Xが10ストローク以上となる
ことは稀であるため,使用に関して予測の遅さが問題になることは
ほとんどない.
またDMでは予測のために時間がかかるのは
グラフィックインタフェースに予測を用いる研究が近年盛んに
行なわれているが,
グラフィックインタフェースにおいては
ユーザの意図を正しく理解することは本質的に困難であるため
[1],
システムが間違った推論を行なわないようにするため
問題を簡単化したりヒューリスティクスを使ったり
頻繁にユーザに問いあわせを行なったりしているものが多い
[14].
これに対し本システムではテキスト操作に限ってはいるものの
簡単な規則で予測インタフェースが成功している.
この大きな理由のひとつとして,Emacsではユーザの意図と操作が
ほぼ1対1に対応している点がある思われる.
Emacsでは例えばユーザがカーソルを行頭に動かしたい場合は
近年提案されている各種の例示/予測インタフェース手法に比べると
文書の入力/編集作業において
DMの実装,評価にあたり数多くの有益な助言をいただいた
長岡技術科学大学の太和田誠氏ならびに
シャープ株式会社の舟渡信彦氏,市川雄二氏,及び今井明氏に
感謝します.
@i[text]'' (Scribeのイタリック指令)を
``{\sl text}'' (TeXのイタリック指令)
に変換することが目標である.
検索/修正操作を1回実行してから
2回目の操作の最初の部分を実行した後を入力するだけで
残りの操作が自動的に行なわれる.
操作前と操作後の文字列の組をシステムに提示しなければならない
Nixのシステムと異なり,通常の編集作業以外のユーザ操作は
のみである.

2.3.3. 関数へのコメント追加
を入力すると
(b)のような結果が得られ,以後を入力する度に次の関数の
先頭にコメントが挿入される.

2.3.4. DM試用ウィンドウ
としてControl-Tを使用する。
2.4. DMの利点
のみである.また繰り返し操作において
どの時点でを入力しても同様の結果が得られる.
が入力されない限り操作の履歴を保持するだけでよいし,
規則1,規則2は高速に実行することが可能である.
履歴保持のオーバーヘッド及び計算コストについては
5.2節で詳しく述べる.
を入力しない限り予測は実行されないので
予測機能を使わないユーザの邪魔になることがない.
2.5. DMの問題点

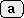
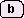
 の後でを入力すると
規則1が適用されてが実行されるが,ユーザは
を期待しているかもしれない.
規則2が規則1より優先するようにすればこの場合ユーザの期待どおりに
なるかもしれないが,
``
の後でを入力すると
規則1が適用されてが実行されるが,ユーザは
を期待しているかもしれない.
規則2が規則1より優先するようにすればこの場合ユーザの期待どおりに
なるかもしれないが,
``bab long-forgotten-sequence abab''
のような操作の後でを入力すると,
``ab''のかわりに忘れられた昔の操作列が実行されてしまうことに
なり望ましくない.
また,
``abracadabra ab''の後でを入力した場合,
ユーザは``racadabra ''を期待しているかもしれないが,
規則2により``ra ''が実行される.
DMは予測手法のひとつであるため,どんな場合でも
ユーザの期待通りの動作をするような仕様を設定することは不可能であるが,
この問題は新たに「予測キー」(以降 と表記)
を導入することにより解決する.
と表記)
を導入することにより解決する.
3. DMと既存の予測手法の融合
3.1. 既存の予測手法
dabbrev機能が広く使用されている.
これらの例のいくつかを図5に示す.
名前 システム 予測に使用する情報
dabbrev Emacs 文書中の文字列
completion Emacs ファイル名など
`` .'' vi 直前のコマンド
`` !!'' csh 直前のコマンド
`` !(string)'' csh コマンド履歴
``ESC l'' tcsh ファイル名
Dynamic Macro (Emacs) 繰り返し操作
Reactive Keyboard shell キー入力の統計情報 )を用いて実装することができる.
次のユーザ入力をファイル名から予測する手法と
辞書エントリから予測する手法を併用した例を
図6に示す.
 が最初に入力された場合はその時点で一番もっともらしい
方式により次の操作を予測してユーザに提示する.
続けてが入力された場合は前の予測を撤回して
次の予測をユーザに提示する.
が最初に入力された場合はその時点で一番もっともらしい
方式により次の操作を予測してユーザに提示する.
続けてが入力された場合は前の予測を撤回して
次の予測をユーザに提示する.
3.2. 予測キーと繰返しキーの併用
とを併用することにより,
前節で述べたDMの問題点が解決されるだけでなく,
さらに複雑な各種の予測手法を使うことが可能になる.
DMの最大の欠点は,予測がユーザの期待と異なっていたとき
修正不可能なことであったが,
を用いることにより,
期待と異なる予測が得られた場合の動作を変更することができる.
前節で述べたように,
の後でを入力すると規則1が適用され
が予測されるが,
この状態でを入力すると次侯補である規則2が
適用されるようにすると,
が予測されるようになる.
これがユーザの期待と一致する場合は,この後再び
を入力することによりこの予測結果を繰り返させることが
できる.この様子を図7に示す.
 の意味を拡張し,が押された後で
が入力された場合は直前の予測方式を繰り返すことにすると,
図9のように,
で予測手法を選択した後でその実行を
繰り返させることができる.
の意味を拡張し,が押された後で
が入力された場合は直前の予測方式を繰り返すことにすると,
図9のように,
で予測手法を選択した後でその実行を
繰り返させることができる.
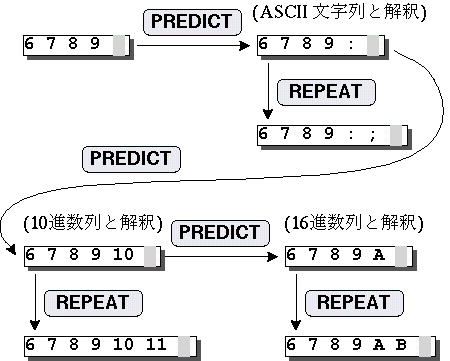 が入力されたときシステムはその前の入力列を
ASCII文字列と判断して``
が入力されたときシステムはその前の入力列を
ASCII文字列と判断して`` ''を予測し実行する.
このときシステムは``ASCII文字列予測モード''になっているため,
ここでユーザはを入力することにより
次のASCII文字``; ''を予測させることができる.
最初の予測がユーザの期待と異なっていた場合,
ユーザがもう一度を入力するとシステムは今度は
前の入力列を10進文字列と判断して``10進数予測モード''となり
``10 ''を予測し実行する.
これがユーザの期待と一致していた場合は
を入力することにより
``11 '', ``12 '', ... を順に予測させることができる.
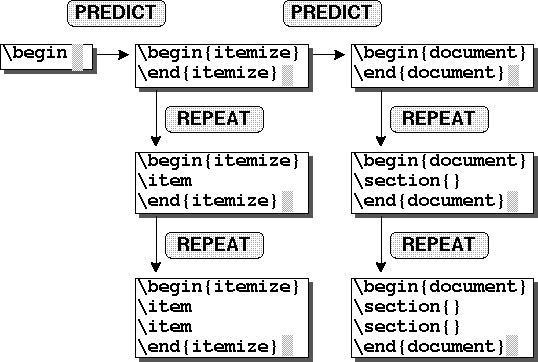
が押されると
``\begin''からitemize環境であると判断して
itemizeモードに状態遷移しつつ
``\begin{itemize}'' ... ``\end{itemize}''を予測する.
このモードにおいてが入力されると
システムは``\item''を予測する.
ユーザの期待がitemizeでなかった場合,
ユーザが最初のに引き続いてもう一度を
入力すると,今度はシステムはdocumentモードに遷移しつつ
``\begin{document}'' ... ``\end{document}''を予測する.
ここでが入力されると
システムはモードの知識により``\section{}''を予測する.
 との機能を整理すると
図11のようになる.
との機能を整理すると
図11のようになる.
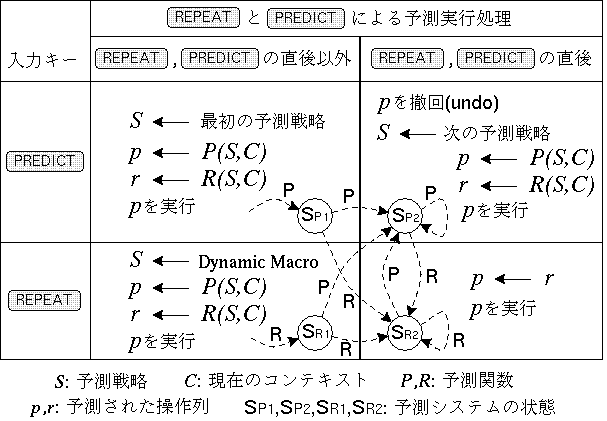 とが押されたとき実行すべき操作列を
S及びCから計算する関数,
p,rは計算された操作列を保持するための変数を示す.
Sp1, Sp2, Sr1, Sr2は
とが押されたときの遷移状態を示し,
図11の遷移図のように状態遷移する.
例えば初期状態においてが入力されるとシステムは状態
Sr1に遷移し,
予測戦略としてDMを選択し,これにもとづいて
操作列を予測し実行する.
そこでが入力されると状態は
Sp2に遷移し,前の予測を撤回して
新たな予測を実行する.
このようにとを併用していろいろな
順番で使用することにより,DMの欠点が解消されかつ
各種の予測手法を適用することができる.
とが押されたとき実行すべき操作列を
S及びCから計算する関数,
p,rは計算された操作列を保持するための変数を示す.
Sp1, Sp2, Sr1, Sr2は
とが押されたときの遷移状態を示し,
図11の遷移図のように状態遷移する.
例えば初期状態においてが入力されるとシステムは状態
Sr1に遷移し,
予測戦略としてDMを選択し,これにもとづいて
操作列を予測し実行する.
そこでが入力されると状態は
Sp2に遷移し,前の予測を撤回して
新たな予測を実行する.
このようにとを併用していろいろな
順番で使用することにより,DMの欠点が解消されかつ
各種の予測手法を適用することができる.
4. 評価
またはによる
システムの予測がユーザの期待と一致する割合)はユーザにより
かなり異なっていた.
最高は100%であったが,このユーザはごく稀に(月に数回)しか予測機能を
使用せず,またその際には非常に慎重に入力を行なっていた.
逆に,間違った予測にはundoで対処すればよいと考えるユーザは
気軽に予測インタフェースを使用するが,的中率は低かった.
平均すると的中率は約85%であった.
により予測されるキーストローク長の平均値は
約5であり,キーストローク数が3または4の予測が最も多かった.
これはDMによる予測方式が,短いキー操作列の繰り返しに対し
効果的であることを示している.
長いキー操作列の繰り返しに対してはキーボードマクロが有効であり,
ごく短いキー操作列の繰り返しに対してはマクロ定義が無意味であるが,
DMはその中間程度のキー操作列の繰り返しに対し有効であることが
わかる.
5. 議論
5.1. 予測インタフェースの条件
undoにより取り消すことが
できるためユーザが不安を感じることはない*.
このように本システムは上述の要件をすべて満たしている.
*次の操作を予測可能であることを
音や表示によりユーザに知らせるシステムも提案されているが
[2]
[4]
[8],
予測機能にあまり頼らないユーザにとってはかえって迷惑となる
ことの方が多い.
5.2. 履歴保持のオーバーヘッドと予測のための計算コスト
(recent-keys)関数で参照することができるため,
これを用いてDMを実装しているが,
このとき規則1では50キーストローク,
規則2では最高99キーストロークまでの繰り返しパタンを
認識可能ということになる.
実際には50キーストロークにも及ぶ操作を繰り返すことは稀であるから
履歴はこの程度保持しておけば充分であり,
そのためのオーバーヘッドは小さい.
を最初に
押したときのみで,続けてを押したときは予測のための
時間はかからないため
5.1節の要件3が満足されている
ことになる.
これに対し,各キーの入力時にキーストローク履歴の部分文字列を
トライ構造などで記憶しておけば規則1/規則2の実行は高速になるが,
あらゆるキーストロークに対しこのような処理を行なうと
要件3が満たされなくなる可能性があるため
得策ではないと考えられる.
5.3. かな漢字変換との類似性
はかな漢字変換方式の
日本語入力システムにおける
「漢字変換キー」または「次侯補キー」と似た動作をする.
実際「漢字変換キー」を図6と同じように使って
ローマ字文字列をかな文字列,漢字文字列に順次変換していくような
かな漢字変換システムも存在する.
このような性質のためは
かな漢字変換システムに慣れたユーザにとってなじみやすいし,
また本システムのような予測インタフェースを
かな漢字変換システムと融合して使用することも可能である.
5.4. DMが効果的に働く理由
を
入力するし,左に何文字か移動させたい場合は を文字の
数だけ入力する.
このように,Emacsでは同じようにカーソルを左に動かす場合でも
その意図によりユーザの操作は異なっているのが普通である.
これに対しグラフィックの直接操作インタフェースでは,
例えば図形をマウスで左にドラッグしたとき,
それが画面の右に場所を空けるためなのか,
移動量が重要なのか,
別の図形と位置を揃えるためなのか,
などが操作のみからは判断がむずかしいため
推論が困難になっているわけである.
Emacsではユーザの意図を反映した機能が別々の操作として
あらかじめ用意されておりそれをユーザが実際に区別して使用するため,
システムがユーザの意図をくみとって予測を行ないやすいということができる.
この点を考慮すると,
グラフィックインタフェースにおいてもユーザがその意図を
常に無意識にシステムに知らせ続けることができれば
効果的な予測インタフェースが構築できると考えられる.
を文字の
数だけ入力する.
このように,Emacsでは同じようにカーソルを左に動かす場合でも
その意図によりユーザの操作は異なっているのが普通である.
これに対しグラフィックの直接操作インタフェースでは,
例えば図形をマウスで左にドラッグしたとき,
それが画面の右に場所を空けるためなのか,
移動量が重要なのか,
別の図形と位置を揃えるためなのか,
などが操作のみからは判断がむずかしいため
推論が困難になっているわけである.
Emacsではユーザの意図を反映した機能が別々の操作として
あらかじめ用意されておりそれをユーザが実際に区別して使用するため,
システムがユーザの意図をくみとって予測を行ないやすいということができる.
この点を考慮すると,
グラフィックインタフェースにおいてもユーザがその意図を
常に無意識にシステムに知らせ続けることができれば
効果的な予測インタフェースが構築できると考えられる.
5.5. 本方式の限界
とによる予測手法は貧弱である.
予測手法はその実行時点における操作履歴や
コンテキストのみから決定しなければならず,
複数の例を使ったり以前の予測を参考にしたりすることが
できないため,
汎化を行なったり条件判断動作をさせることができない.
またユーザは予測結果のみを見て予測手法が適当かどうか
判断しなければならないが,常に予測方式を予測結果から
正しく判断できるとは限らない.
また一度選択した予測手法は後で編集したり再利用することが
できないため,どうしても使われるのは簡単な予測手法ばかり
ということになってしまう.
本方式は,強力な予測を行ないたい場合よりは,
単純な予測を手軽に使いたい場合に有効だということができる.
6. 結論
とというふたつのキーのみを用いる
予測インタフェース手法を提案した.
本手法は単純であるにもかかわらずキーボードマクロをはじめとする
従来の各種手法にない特長を持っており適用範囲が広い.
今後は本手法を文書編集以外の領域にも適用していく予定である.
7. 謝辞
Up$Date: 1996/05/18 15:11:16 $
増井の論文リスト